The logic is actually fairly simple. Y_hat represents the predicted score for X_i, the current index/value being considered. If y_hat is correctly classified, multiplying it by y_i should yield True, equal to 1 in Python. The other part of the equation checks to see if this product is less than 1 (using 1s and -1s instead of 1s and 0s for our y values makes this possible). If it is, this expression will evaluate to True, which is equal to 1 in Python.
Only one of these expressions is true at any given time. When False, these evaluate to zero.
If the first expression is True, aka when it is equivalent to 1, it preserves the current weight vector, while the second expression, equal to zero, nullifies its coefficient.
When the second expression is True and therefore equal to 1, it is multiplied by the sum of w_i (the current weight vector) and the product of the feature matrix (X) at index i, and the classification matrix (y) at index i. This sounds complicated, but really this line of code is just either keeping the old weight vector if it classified point i correctly, or adding or subtracting the value it incorrectly classified to ensure that it classifies it correctly in the next iteration.
This logic is the same in the update method. The only difference is that update accepts a weight vector as a parameter, running only a single step of the Perceptron algorithm rather than to completion.
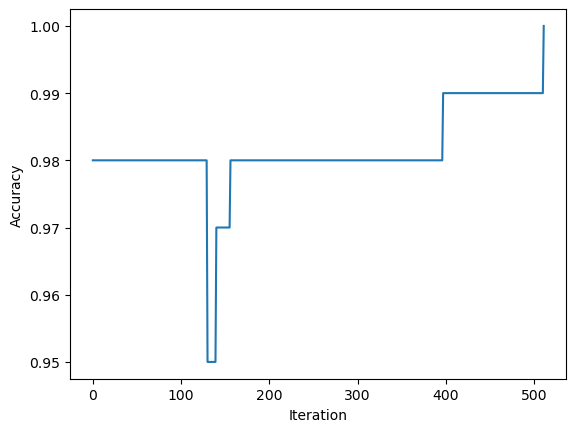
If the data are linearly separable, then the perceptron algorithm will converge.
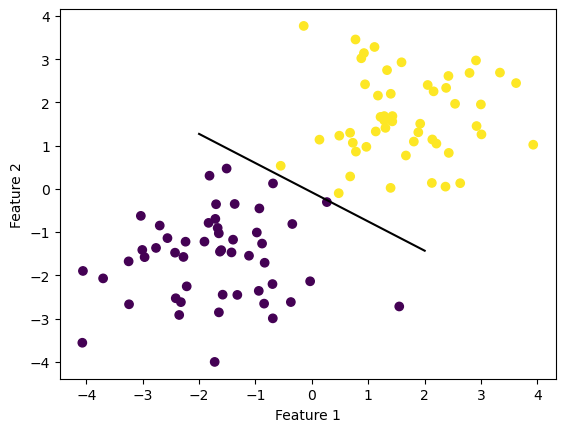
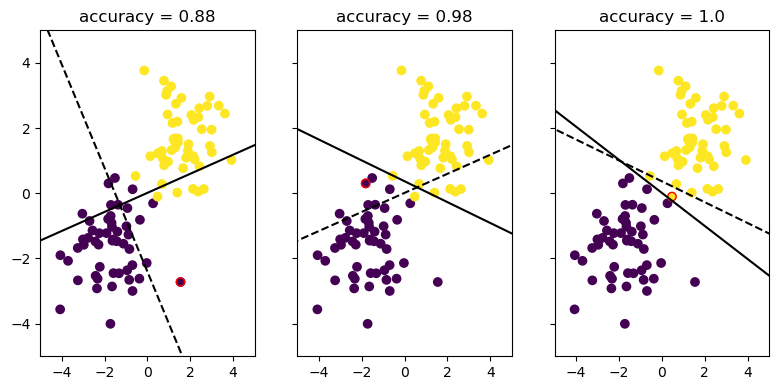
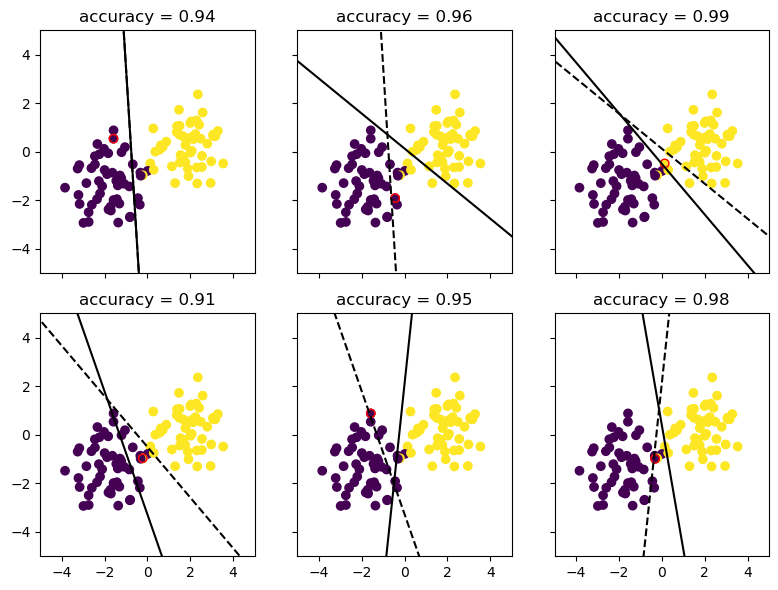
Let’s vizualise the process of improvement by showing the progression of the Perceptron algorithm over time.
These three plots only show instances where the weight vector updates (that is to say, when the algorithm misclassifies a point and updates the weight vector to reflect this). This ensures that we actually see how the Perceptron algorithm corrects itself over time. Otherwise, we might just see three cases where it correctly classifies a point and nothing changes. BORING!!!
We can see that the algorithm still updates and tries to correct itself, but is unable to achieve 100% accuracy. Including more subplots helps to show that this process of guessing but never achieving convergence will continue infinitely.
It works! It makes sense that it wouldn’t achieve convergence on a completely random set of points and classifications.
It is worth asking, though, is it theoretically possible to have a linearly separable set of points in 5 (or more) dimensions?
It is pretty straightforward to see that this is possible in 3 dimensions - imagine a flat plane separating 2 clouds of points in 3 dimensions.
In 5 dimensions, all that this means is that the weight vector multiplied by the feature matrix correctly classifies each point – either one or zero. One does not need to imagine what a 5D physical space might look like to see that this is certainly achievable.
Perceptron Runtime
Finally, let’s consider the question of how long it takes for the update step to run.
What is actually happening? Just multiplication and some logical comparisons, really – we check to see if mathematically the product of our weight vector and the feature matrix evaluates to what we would expect it to be, and if not, we perform some simple matrix multiplication and addition to get our new weight vector. This is dependent on the number of features (p), but not on the number of points (n). Therefore, this operation takes O(p) time. It does not matter how many points there are, because we are only focusing on a single data point at a time, and updating only relative to that point. So the only variable impacting the time complexity of this operation is p – the number of features.